12.5 Application: Amazon Book Reviews
The R-package tigerData (White 2018) contains the data set reviews, a collection of user-reviews on Amazon for seven bestsellers. Learn more about the data set as follows:
library(tigerData)
help(reviews)Each row of the data frame contains:
- the 1-5 rating that the reviewer assigned to the book
- a URL fragment that locates the review online;
- the summary-title of the review;
- the content of the review itself.
Let’s focus on reviews for Hunger Games series. The following code creates a new data frame that contains only those reviews:
hunger <- subset(reviews, book == "hunger")That’s still a lot of reviews! We can tell by asking for the number of rows in the hunger data frame:
nrow(hunger)## [1] 24027We are looking at 24,027 reviews—some of which, by the way, are quite long.
Explore the plain-text of some of the reviews. For example, the text of the second review can be viewed with:
hunger$content[2]## # A single long string. We will show just the first few characters:
## [1] "\"<span class=\"\"a-size-base review-text\"\">Clearly ...Perusing this review, we come upon the following passage:
There is a certain strain of book that can hypnotize you into believing that you are in another time and place roughly 2.3 seconds after you put that book down. <a class=\“\”a-link-normal\“\” href=""/Life-As-We-Knew-It/dp/0152061541\“\”>Life As We Knew It by Susan Beth Pfeffer could convince me that there were simply not enough canned goods in my home.
The author has linked to another book sold on Amazon, Susan Beth Pfeffer’s Life As We Knew It. The Amazon.com URL for the book is found by prepending the company’s domain to the URL-fragment seen in the excerpt above, resulting in the link:
We might be curious to know what other books on Amazon our reviewers link to when they are discussing the Hunger Games. Regular expressions can help us to extract the links from the mass of text in hunger$content.
All of the Amazon links are generated for the user by the computer, so they will all have the same format. Hence we can use a look-behind and a look-ahead to construct a regex that will be matched by any URL-fragment within such an anchor:
(?<=<a class=\\"\\"a-link-normal\\"\\" href=\\"\\")(.+?)(?=\\"\\">)
Checking carefully, we see that none of the tokens require extra escaping: we can use this text as our pattern in regex function in R:
linkPattern <- '(?<=<a class=\\"\\"a-link-normal\\"\\" href=\\"\\")(.+?)(?=\\"\\">)'First we create a new variable in hunger that counts the number of links in a review:
hungerLinks <-
hunger %>%
mutate(linkCount = str_count(content, linkPattern))Now we can tally the number of links:
hungerLinks %>%
group_by(linkCount) %>%
summarise(n = n())## # A tibble: 10 x 2
## linkCount n
## <int> <int>
## 1 0 23854
## 2 1 110
## 3 2 34
## 4 3 15
## 5 4 7
## 6 5 3
## 7 6 1
## 8 7 1
## 9 8 1
## 10 9 1If you are generating a report with R Markdown, then a better-looking table (see Table 12.4 can be produced as follows:
hungerLinks %>%
group_by(linkCount) %>%
summarise(n = n()) %>%
knitr::kable(caption=str_c("Table showing number of links ",
"made by reviewers of the Hunger ",
"Games series."))| linkCount | n |
|---|---|
| 0 | 23854 |
| 1 | 110 |
| 2 | 34 |
| 3 | 15 |
| 4 | 7 |
| 5 | 3 |
| 6 | 1 |
| 7 | 1 |
| 8 | 1 |
| 9 | 1 |
Most of the reviewers didn’t link at all, but 173 of them did provide at least one link. One reviewer linked to nine books! Let’s find them and add the base URL http://www.amazon.com/:
hungerLinks %>%
filter(linkCount == max(linkCount)) %>% # get the case having most links
.$content %>% # get just the content of the review,
# a character vector (of length 1 since there
# is only one review with the max number of lengths)
str_extract_all(pattern = linkPattern) %>% # get the matches,
# but this is a list of
# length 1 ...
unlist() %>% # ... so unlist it into a character vector
str_c("http://www.amazon.com/", .) # prepend the base URL to each link## [1] "http://www.amazon.com//Harry-Potter-Paperback-Box-Set-Books-1-7/dp/0545162076"
## [2] "http://www.amazon.com//The-Dark-Tower-Boxed-Set-Books-1-4/dp/0451211243"
## [3] "http://www.amazon.com//The-Long-Walk/dp/0451196716"
## [4] "http://www.amazon.com//Battle-Royale-The-Novel/dp/1421527723"
## [5] "http://www.amazon.com//Battle-Royale-The-Complete-Collection-Blu-ray/dp/B006L4MX4A"
## [6] "http://www.amazon.com//The-Dark-Tower-Boxed-Set-Books-1-4/dp/0451211243"
## [7] "http://www.amazon.com//Harry-Potter-Paperback-Box-Set-Books-1-7/dp/0545162076"
## [8] "http://www.amazon.com//Abarat/dp/0062094106"
## [9] "http://www.amazon.com//lord-of-the-flies/dp/B0073SQWWC"As we learn more about R’s data-analysis functions we’ll be able to explore a wide variety of interesting questions about the attitudes and practices of Amazon reviewers. This will involve plowing through a lot more text, but now that we know regular expressions we are sure to “save the day!”
12.5.1 Practice Exercises
Use
reviewsto generate a table of the the number of Amazon links in reviews of John Greene’s book The Fault in our Stars.How many times did a reviewer link to Looking for Alaska (another well-known book by John Greene)?
From
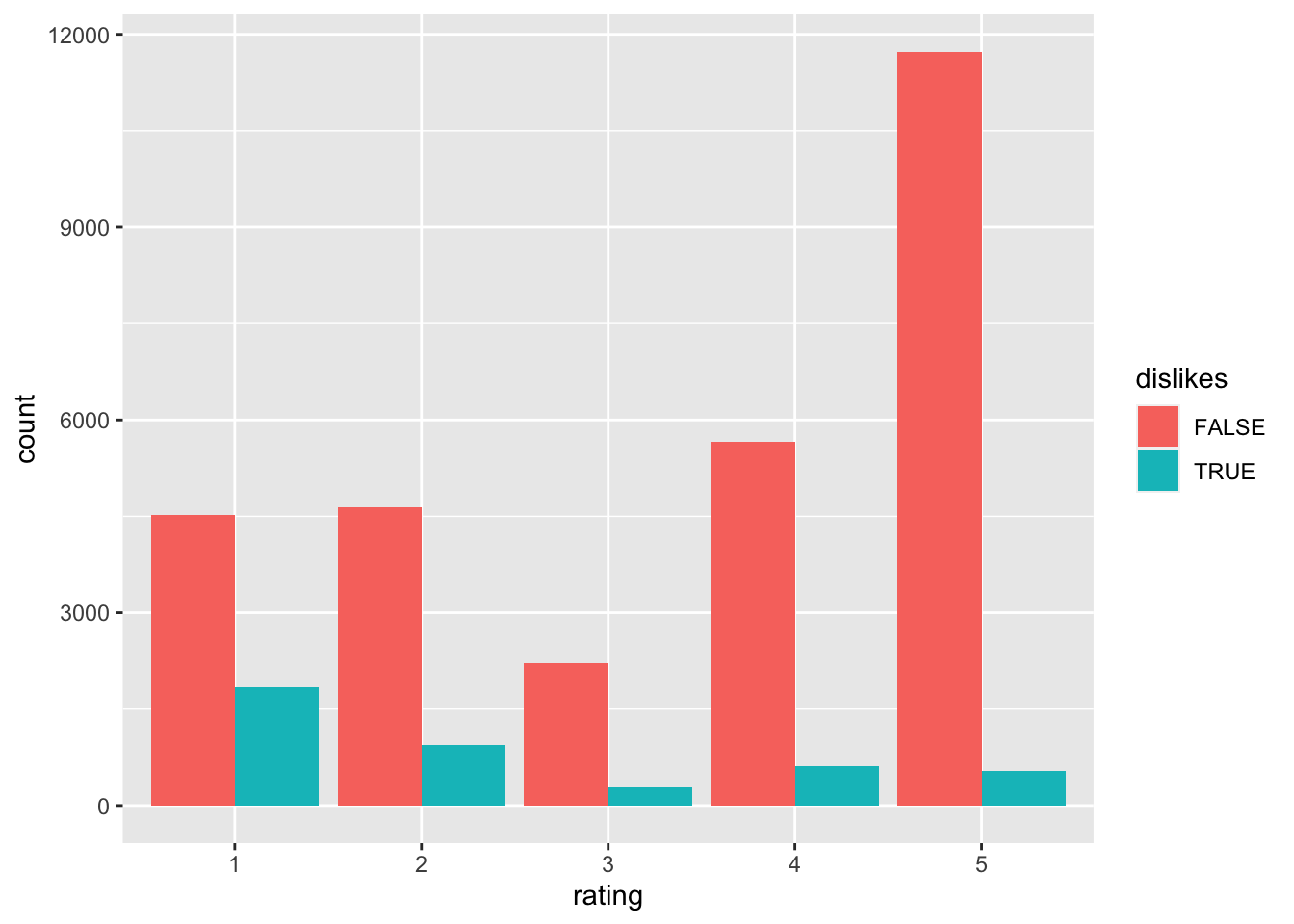
reviews, make a data frame called shades that contains the reviews of Fifty Shades of Gray. This bestseller received an unusually high proportion of low ratings. Think of a few choice words that might show up in a negative review and create a logical variable calleddislikesthat isTRUEwhen one or more of these words appears in the review, and isFALSEotherwise. Convert the numerical variableratingto a factor variable. Make a bar graph that shows the relation betweendislikesandrating.
12.5.2 Solutions to the Practice Exercises
Try this:
linkPattern <- "(?<=<a class=\"\"a-link-normal\"\" href=\"\"/)(.+?)(?=\"\">)" fault <- reviews %>% filter(book == "fault") fault %>% mutate(linkCount = str_count(content, linkPattern)) %>% group_by(linkCount) %>% summarise(n = n())## # A tibble: 6 x 2 ## linkCount n ## <int> <int> ## 1 0 35827 ## 2 1 10 ## 3 2 3 ## 4 3 2 ## 5 6 1 ## 6 7 1Try this:
fault %>% .$content %>% str_extract_all(pattern = linkPattern) %>% unlist() %>% str_detect("(?i)Looking-For-Alaska") %>% sum()## [1] 5Here is one possibility:
reviews %>% filter(book == "shades") %>% mutate(dislikes = str_detect(content, "bad|awful|terrible|waste")) %>% mutate(rating = factor(rating)) %>% ggplot(aes(x = rating)) + geom_bar(aes(fill = dislikes), position = "dodge")