12 Regular Expressions

Figure 12.1: Regular Expressions, by xkcd.
In this Chapter we introduce the concept of regular expressions, a powerful tool that enables you to search for complex patterns in text. We will continue to use functions from the stringr package.
12.1 Motivation
Suppose you wish to determine how many times the string “ab” appears within some given string. You could write a function to perform this task.
occurrences <- function(string) {
count <- 0
for (i in 1:str_length(string)) {
stringPart <- str_sub(string, i, i+1)
if (stringPart == "ab") {
count <- count + 1
}
}
count
}Let’s try it out:
occurrences("yabbadabbadoo!")## [1] 2This looks right, as there are indeed exactly two occurrences of “ab”: one at beginning at the second character and another beginning at the seventh character.
Suppose instead that we are interested in counting occurrences, in some arbitrary given string, of any of the following three strings:
- “ab”
- “Ab”
- “foo”
How might we handle this task? Again we could write a function. This time we will generalize it a bit, allowing the user to input, along with the string to be searched, a vector of the sub-strings of interest.
# function to count occurrences of substrings in string.
# substrings are given as patterns
occurrences2 <- function(string, patterns) {
count <- 0
for (i in 1:str_length(string)) {
for (j in 1:length(patterns)) {
pattern <- patterns[j]
len <- str_length(pattern)
stringPart <- str_sub(string, i, i + len - 1)
if (stringPart == pattern) {
count <- count +1
}
}
}
count
}We try out our function on the string “This Labrador is a fool, Abba.”, which matches each of our patterns exactly once, for a total of three matches,
occurrences2("This Labrador is a fool, Abba.",
patterns = c("ab", "Ab", "foo"))## [1] 3Well, and good, but … the coding is beginning to get a bit complex. What if we were searching instead for, say, sub-strings that resemble a phone number with an area code, i.e., strings of the form:
ddd-ddd-dddd
(Here the d’s represent digits from 0 to 9.)
There are \(10^{10}\) patterns of interest!29 How would we go about describing them all to R?
Fortunately, regular expressions are there to help us out. A regular expression is defined as a sequence of characters that represents a pattern that might or might not be present in any given string. A computer will rely on a regular expression engine—a specific implementation of a system of regular expressions—to use a given regular expression to search in text for matches to the pattern that the expression represents.
In practice, regular expressions are like a miniature programming language within a programming language. They are a feature of most major programming languages, including R. With regular expressions we can describe complex string-patterns concisely, and can perform rapid searches for these patterns in a given body of text.
The rules for regular expressions vary a bit from one language to another, but the general idea is essentially the same for all of them. In the remainder of this Chapter we’ll learn enough of the principles of regular expressions to describe basic, useful patterns, and we’ll also study R-functions that make use of them.
First of all, here’s a quick example to show the power of regular expressions. The work done by occurences2() may also be done in one line with the str_count() function, as follows:
str_count(
string = "This Labrador is a fool, Abba.",
pattern = "[Aa]b|foo"
)## [1] 3Wow, that was quick. But what in the world is that "[Aa]b|foo" argument to the pattern parameter?
It’s a regular expression! It tells R to look for sub-strings that EITHER:
- start with either “A” or “a”, and are then followed by a “b”, OR
- consist of “foo”
Clearly it is high time that we learn a bit of regular-expression syntax.
12.2 Regex Practice Sites
As we introduce regex syntax in the next few sections, it’s a good idea to try them out yourself and to come up with your own variations. The easiest way to do this is not to work directly in R at the outset; instead, consider using an online regex practice site. I especially recommend RegExr, which has a nice documentation interface. Set the regex flavor to PCRE, as this is the variant of regular expression syntax that is closest to the ICU regex variant used by the stringr package. If you go on to Web Programming course then you can switch to the JavaScript flavor.
Bear in mind also that as we learn regex syntax, we’ll focus on the standard, language-independent syntax itself. There are some differences between this standard syntax and the way in which you would actually enter a regex pattern in R.
12.3 Regex Syntax
Let’s start learning the syntax.
12.3.1 Matching a Specific Sequence
If you are searching for occurrences of one specific sequence of characters, the regular expression to use is just that sequence of characters.
For example, if your regex is bet, then you’ll get a match whenever the characters “b”, “e”, and “t” occur consecutively in the text you are searching.
In the sample text below, the matches are in italics:
I bet you are reading between the lines. Better to read the lines themselves.
We didn’t match “Bet” in “Better” because “B” is uppercase.
The characters “b”, “e” and “t” in the regex “bet” are examples of literal characters. This means that they stand for exactly what they are: the “b” in the expression matches a “b” in the text we are searching, the “e” in the expression matches an “e” in text, and so on.
There are a lot of exceptions to our specific-sequence rule. We’ll get to them soon.
12.3.2 Character Classes
Suppose you want to match either “bet” or “Bet”? One way to do this is to use a character class. A character class consists of a set of characters surrounded by square brackets, and it tells the regex engine to match any one of the characters in the class.
Consider, for example, the regex [Bb]et. It consists of the character class [Bb] followed by the pair of literal characters et. It matches:
I bet you are reading between the lines. Better to read the lines themselves.
Another example: t[aeiou] matches any two-character sequence in which “t” is followed by a lowercase vowel:
Get thee to a nunnery.
12.3.2.1 Ranges
You can match a range of characters. Inside a character class:
-
a-zrepresents all lowercase letters from a to z; -
A-Zrepresents all of the uppercase letters; -
0-9represents all of the decimal digits: 0, 1, 2, …, 9. - Other ranges are possible, e.g.:
-
c-fdenotes the lowercase letters from c to f; -
0-3denotes 0, 1, 2 and 3.
-
Thus, in order to match any letter followed by two digits, you could use [a-zA-Z][0-9][0-9]:
Your room number is B43, not C4 or #39.
12.3.2.2 The Need to Escape
Perhaps now you can spot the problem with the sequence-specific rule: what happens if one of the characters in the sequence is, say ‘[’ or ’]’? These characters are examples of metacharacters, which means that in the syntax of regular expressions they don’t match themselves but instead have a special role. In the case of square-brackets, that role is to delimit character classes.
If you want your pattern to include a metacharacter you will have to escape it with the backslash. Thus, the correct way to match the string “[aardvark]” would be with the regular expression: \[aardvark\]:
The [aardvark] appears early in the dictionary.
Actually, you only need to escape a metacharacter when it acts in its role as metacharacter. For example, if you want to match “b-b”, you are fine to use b-b. Because the expression contains no square brackets, it’s not possible for the hyphen to act in its special role to set ranges, so it does not have to be escaped.
Inside of square brackets it can matter whether you escape the hyphen. Thus:
-
[a-c]matches a, b, and c; -
[a\-c]matches a, -, and c (but not b); -
[a-]matches a and - (the machine can tell that the hyphen was not being used in a range); -
[a\-]also matches just a and -, not a, \ and -. (Apparently the regex syntax takes into account the fact that some folks will worry that they might have to escape the hyphen).
Of course since the backslash plays a role in escaping metacharacters, it too acts as a metacharacter at times. Hence if you want to match a backslash you’ll have to escape it! How? By preceding the black-slash with a backslash! Thus:
-
a\\bmatches “a\b”; -
a\\\\bmatches “a\\b”.
On the other hand:
-
a\tbmatches a followed by a tab followed by b, because in this case the machine recognizes\tas the control character for a tab; -
a\abmatches a followed by the bell-alert followed by b, and so on for other control characters.
But keep the following in mind:
-
a\ebis incorrect regex syntax:\eis not recognized as one of the control characters. - And yet
a\wbis correct regex syntax! (It turns out that the token\wis a recognized character class shortcut that means the same as[a-zA-Z0-9_](all of the lowercase and uppercase letters, the digits, and the underscore character). We’ll get to the shortcuts soon.
12.3.2.3 Named Character Classes
Some character classes occur so commonly that they have been granted special names. Table 12.1 gives a few that are worth remembering.
| Class Name | Represents |
|---|---|
| [:alpha:] | a-zA-Z |
| [:alnum:] | a-zA-Z0-9 |
| [:word:] | a-zA-Z0-9_ (note the underscore) |
| [:space:] | white space |
| [:lower:] | a-z |
| [:upper:] | A-Z |
Here’s how you would use character class names in a regular expression:
-
t[[:alnum:]]tmatches t followed by any alphanumeric character followed by t. (The double brackets are needed since, according to the rules,t[:alnum:]twould match t followed by any one of :, a, l, n, u or m, followed by t.)
12.3.2.4 Character Class Shortcuts
Some character classes are so very common that they merit extra-short shortcuts: most of these shortcuts begin with a backslash. We’ll call them character class shortcuts. Some of the most common character class shortcuts are shown in Table 12.2
| Type | Represents |
|---|---|
| \d | any decimal digit (0-9) |
| \D | anything not a decimal digit |
| \s | any white space character |
| \S | anything not a white space character |
| \w | any word character (same as [word]) |
| \W | anything not a word character |
| . | any character except newline |
The . requires special care: if you are searching for a literal dot, you’ll have to escape it with a backslash. Thus 32\.456 matches “32.456”, whereas 32.456 matches “32a456”, 32b456”, and so on.
12.3.2.5 Negation in a Character Class
Suppose you would like to match any sequence of three characters of this form:
- t
- any character EXCEPT e, x and z
- t
You can accomplish this by negating within a character class: the regex to use is t[^exz]t. Here the caret ^ functions as a metacharacter, indicating that any character except the others in the class are permitted. In order to function as a negation, the ^ must appear immediately after the opening bracket. If it appears elsewhere in the class, then it’s a literal: it just stands for itself. (Outside of a character class the ^ functions as an anchor—we’ll get to these soon—and as such has to be escaped if you want to act as a literal.)
As another example, t[^a-z]t matches t followed by any character expect a lowercase letter, followed by t.
Negating within a particular class of characters can be tricky. For example, suppose you are looking for 3-character sequences that consist of t, any letter except e or E, and then t. Rather than trying to use a ^ it’s easiest to work with ranges: t[a-df-zA-DF-Z]t.
12.3.3 Quantification
Suppose you want to match phone numbers, where the area code is included and the groups of digits are separated by hyphens, as in: 202-456-1111. Taking advantage of the character class shortcut for digits, you could use the following regex:
\d\d\d-\d\d\d-\d\d\d\d
But that’s a bit difficult to read. And besides, what if you weren’t working with phone numbers but instead wanted to match sequences like the following (which has 10 digits in succession)?
A2356737821
It would be awful to write A\d\d\d\d\d\d\d\d\d\d.
This is where quantifiers come in. In regular expression syntax a token of the form {n} indicates that we are looking for n consecutive copies of whatever token precedes the {n}. Thus we can write the phone-number regex more concisely and more legibly as:
\d{3}-\d{3}-\d{4}
Note that the curly braces { and } may now function as metacharacters, and as such may have to be escaped if you are looking for them specifically, Thus if you want to search for occurrences of “t{3}b”, you’ll need the regex t\{3\}b. On the other hand if you want to match “t{swim}b” then it’s fine to use the regex t{swim}b: the machine sees here that the braces don’t play a role in quantification.
Quantifiers are quite flexible. Within a quantifier you can use a comma to indicate a range of permissible number of copies of the preceding expression:
-
t{3,5}matches 3, 4 or 5 t’s in succession: ttt, tttt, or ttttt; -
t{3,}matches three or more t’s in succession: ttt, tttt, ttttt, … .
Because quantification is so often required, regular expression syntax provides shortcuts for special cases:
-
t*matches 0 or more t’s; -
t+matches one or more t’s; -
t?matches 0 or 1 t.
An example: to match the beginning of a URL, use https?://:
The URL https://example.org provides authentication of the site, whereas you should not pay with a credit card on http://flybynight.com, On the other hand htto://example.org is not a valid URL—it’s probably a typo.
Note that these shortcuts introduce new metacharacters: *, + and ?. You’ll probably need to escape them when you want to search for them as literals outside of a character class.
12.3.4 Greedy vs. Lazy
When it comes to the open-ended quantifiers ({n,} or the shortcuts * and +), the default behavior is to make the longest match possible. This is known as greedy behavior. Consider the matches reported in the following text for b{3,}
b bb bbb bbbb bbbbb
It is possible, however, to tell a quantifier to be lazy, meaning that it should give the shortest possible matches. The way to do this is to append a ? to the quantifier. Applied to the same text above the regex b{3,}? with the lazy quantifier reports a different set of (sometimes shorter) matches:
b bb bbb bbbb bbbbb
12.3.5 Grouping
A quantifier refers to the shortest meaningful item immediately preceding it. Look at these examples:
-
ab+matches “a” followed by 1 or more “b”’s; -
a\d+matches “a” followed by 1 or more digits; -
a[^bc]+matches “a” followed by 1 or more occurrence of anything other than “b” or “c”;
In the examples above, any match begins with “a”. If we want to get “a” into the scope of the quantifier, we have to group it with the item immediately preceding the quantifier. Grouping is accomplished with parentheses. Consider these examples:
-
(ab)+matches one or more occurrences of “ab” in succession; -
(a\d{2,})+matches one or more occurrences of “a” followed by at least two digits. Thus it matches “a23” and “a23a773”. It won’t match “a2a3”. It will match only the “a23” in “a23a6” and it will match only the “a567” in “a4a567”.
Grouping is a great help in constructing highly complex patterns. Bear in mind that the grouping symbols ( and ) function as metacharacters and will have to be escaped outside of character classes when you are searching for them as literals. Inside of character classes they function only as literals. Thus:
-
[(ab)*]matches any one of the following characters: “(”, “a”, “b”, “)” and “*“. -
\(yes\)matches “(yes)”.
12.3.6 Alternation
In regex syntax the symbol | (the vertical “pipe”) functions as a metacharacter meaning or. Thus:
-
a|bmatches “a” and it matches “b”; -
bed|bathmatches “bed” and it matches “bath”; -
a|b|cmatches any one of “a”, “b” and “c”; -
(aa|bb)+matches one or more occurrence of “aa” or “bb”. Thus it matches “aa”, “bb”, “aaaa”, “aabb”, “bbaa”, “bbbb” and so on. -
(a(a|b)b)+matches “aab”, “abb”, “aabaab”, “aababb”, and so on.
Use of the pipe-symbol is known as alternation.
In most implementations of regular expressions alternation works rather slowly, so use character classes instead whenever you can. For example, [a-e] is preferred over a|b|c|d|e.
12.3.7 Anchors
Sometimes we are interested in patterns that occur in specific places in text, such as:
- at the beginning of a string;
- at the end of a string
- at the beginning or end of a word.
Anchors help us accomplish this. The most important anchors to remember are:
-
^, which indicates (in technical terms, asserts) the beginning of a string; -
$, which asserts the end of a string;30 -
\b, which asserts the presence of any type word-boundary (a space, tab, comma, semicolon, etc.).
Here are some examples:
-
For
^Hello:Hello got matched, but not the next Hello.
-
For
Hello$:Hello did not get matched, but there is a match for the next Hello
One thing that’s important to keep in mind about anchors is that they are assertions. This means that they don’t actually count for characters in a match; they merely assert the presence of something: the beginning or end of a string, the boundary of a a word, etc. Thus, there are six tokens in the regular expression ^Hello, but only five characters—the letters in “Hello”—are involved in a match. The^ merely asserts that a match must not only involve the given characters but must also occur at the beginning the string.
What does ^Hello$ match? The rules would say that the string must start with H, continue on with e, l, l and then o, and end there, so you might think that the only possible string containing a match of ^Hello$ is the string “Hello” itself.
But that’s not quite right:
- Go your online regex practice site (Regular Expression 101).
- Enter the regex
hello$. - Then in the “Flags” dropdown menu, check “multiline”.
- You should now see “/gm” at the end of the regular expression. You have entered multiline mode.
- In the test-text field, enter “I say hello”, press Return, and continue on the next line with “Again I say hello”.
- You’ll see that both hello’s match.
The reason for this is that in multiline mode $ stands for the end of each line, not just the absolute end of the string. From time to time you may deal with strings that run over multiple lines, so remember that if you want your ending anchors to represent end-of-line rather than the absolute end of the string, you’ll need to ask R to enter multiline mode. (Later on in the Chapter we’ll discuss some common modes and how to enter them in R.)
The word-boundary anchor \b is quite useful. Consider the regex bed applied to the string below:
bed bedtime perturbed
There are three matches! With the regex \bbed there are just two matches:
bed bedtime perturbed
With the regex \bbed\b the only match is with the actual word “bed”:
bed bedtime perturbed
Note that the beginning and the end of a string count as word-boundaries!
12.3.8 Captures
How would you detect whether a particular instance of a pattern is repeated? For instance, suppose you are looking for occurrences of a word repeated immediately after itself with only a space in between, for example:
- “bye bye birdie”
- “she said night night”
The regex \b\w+\b (word boundary followed by one or more word characters followed by a word boundary) will match words like “bye” and “night”, but if you simply repeated the pattern, say: \b\w+\b \b\w+\b, then you match strings that don’t exhibit repetition, such as “bye hello” and day night”.
What you want is for the first part of the regex to state your pattern—a word of one or more characters—then the space, and then something that represents exactly the match that occurs for the first pattern.
A capture accomplishes this. The regex you want is:
\b(\w+) \1\b
See what it matches in the phrase below:
now it is time for bed bed, yes it is bed bedtime
Here’s how the regex works:
- The leading
\brequires the presence of a word-boundary, which is satisfied by the presence, in the string, of the space between “for” and “bed bed”. The second “bed bed” is also OK at this point, due to the space between “is” and the first “bed”. -
\w+matches the first “bed”, and the parentheses make it a group. By default the regex captures the contents of whatever portion of the string matches a group, and remembers those contents for later use. - The
matches the space between the two “bed” strings. - The
\1is a back-reference: it represents precisely what was matched in the earlier group. For the regex as a whole to produce a match,\1has to see an exact repetition of whatever string matched the first parenthesis-group in the regex, so it has to see “bed”. At this point both occurrences of “bed bed”” are still in the running to be matches for the entire regex. - The final
\basserts a word-boundary. This is satisfied by the comma after the first “bed bed”, but not by the “t” after the second “bed bed”. Thus only the first “bed bed” matches the regular expression as a whole.
Back-references are denoted \1, \2, and so on, and you can use several of them in the same regex. For example, if you want to match expressions such as “big boat big boat” then use:
\b(\w+) (\w+) \1 \2\b
Think about how the above regex works:
- To start, it requires the presence of a word-boundary.
- It sets up a capture-group consisting of one or more word characters. Since this is the first set of parentheses, the group can be referenced later on by
\1. - It then sets up a second capture-group that may be referenced later on by
\2. - We then must see a space …
- … followed by the contents of the first group …
- … followed by the contents of the second group …
- … at a word-boundary.
If you want to match a palindrome31 consisting of five characters (“abcba”, “x444x”, etc.) then use:
\b(\w)(\w)\w\2\1\b
12.3.9 Looking Around
Suppose that you have a string containing a number of words involving “bed”, and you would like to find all occurrences of “bed” that begin a word, except for the word “bedtime”. With the tools we have so far this is a difficult task. Fortunately there are look-aheads to simplify our work.
The regex \bbed(?!time\b) will do the job. Here’s how it works:
- It begins by asserting a word-boundary.
- It continues with the characters to match “bed”.
- It concludes a look-ahead group. The parentheses mark out the group. The initial
?indicates that we plan to look ahead. The!may be thought of as “not equals”; it means that if we find the pattern that follows the!we will not have a match.
Note the matches in the text below:
bedtime bedrock bedrocking bedsheets bedding embedding
Note that only “bed” is included in the match. Just like the anchor \b, the look-ahead is an assertion: it does not add any characters to the match.
If we want only the occurrences of “bed” where the word begins in “bed” and ends in either “rock” and “time”, then we could use the regex:
\bbed(?=rock\b|time\b)
Note the matches in the following text:
bedtime bedrock bedrocking bedsheets bedding embedding
Of course we could locate the same occurrences with \bbed(rock|time)\b, but the matches would be the entire words, not just the “bed” portion.
There are four types of look-around groups:
-
Positive look-ahead: regex1
(?=regex2). Match when you find an instance ofregex2right after an instance ofregex1. -
Negative look-ahead:
regex1(?!regex). Match EXCEPT when you find an instance ofregex2right after an instance ofregex1. -
Positive look-behind:
(?<=regex2)regex1. Match when you find an instance ofregex2right before an instance ofregex1. -
Negative look-behind:
(?<!regex2)regex1. Match EXCEPT when you find an instance ofregex2right before an instance ofregex1.
The regex2 expression in look-aheads can be any regex at all. For look-behinds, though, there are some important limitations. The precise restrictions differ from one flavor of regular expressions to another, but roughly the rule is that the machine has to be able to figure out in advance how many characters it might have to look behind. A group like (?<=time\w*sheets), for instance, would not be permitted, as the quantifier * allows matching strings of arbitrary length.
12.3.10 More to Learn
We have not come near to exhausting the syntax of regular expressions. Readers who would like to delve into the subject more deeply should next consult online tutorials on the topics of non-capture groups, conditionals and more. It would also be good to look at the brief overview of the ICU regex engine provided in stringi-search-regex in the documentation for the stringi package on which stringr is based. However, we now have enough background to express some fairly complex patterns quite concisely, so it is now time to learn how to work with them in R.
12.4 Entering a Regex in R
We now return to the R-language and consider how to apply regular expressions within it.
12.4.1 String to Regex
Regular expressions actually play a role in one of the functions you already know, namely the function strsplit(). Recall that you can use the split parameter to specify the sub-string that separates the strings you want to split up. It works like this:
## [1] "hello" "there" "Mary" "Poppins"The task of splitting would appear to a quite challenging if the words are separated in more complex ways, with any amount of white-space. Consider, for example:
myString <- "hello\t\tthere\n\nMary \t Poppins"
cat(myString)## hello there
##
## Mary PoppinsBut really it’s not any more difficult, because the split parameter actually takes the string it is given and converts it to a regular expression, splitting on anything that matches. Watch this:
## [1] "hello" "there" "Mary" "Poppins"We can almost see how this works. Recall from the last section that the regex \s is a character class shortcut for any white-space character, so \s+ stands for one or more white-spaces in succession: precisely the mixtures of tab, spaces and newlines that separated the words in our string. str_split() must be splitting on matches to the regex \s+.
So why did we set pattern = "\\s+"? What’s with the extra backslash?
The reason is that the argument passed with pattern is a string, not a regular expression object. It starts out life, as if were, as a string, and R converts it to a regular expression, then hands the regex over to its regular expression engine to locate the matches in myString that in turn determine how myString is to be split up. Since in R’s string-world “\s” is not a recognized character in the way that newline (“\n”), tab (“\t”) and other control-characters are, R won’t accept “\s+” as a valid string. Try it for your self:
## Error: '\s' is an unrecognized escape in character string starting ""\s"It follows that when you enter regular expressions as strings in R, you’ll have to remember to escape the back-slashed tokens that are used in a regular expression. Table 12.3 gives several examples of this.
| Regular Expression | Entered as String |
|---|---|
| \s+ | “\\s+” |
| find\.dot | “find\\.dot” |
| ^\w*\d{1,3}$ | “^\\w*\\d{1,3}$” |
Keeping in mind the need for an occasional additional escape, it should not be too difficult for you to enter regular expressions in R.
12.4.2 Replacement
One of the most useful applications of regular expressions is in substitution, also known as replacement.
Suppose that we have a vector of dates:
dates <- c(
"3 - 14 - 1963", "4/13/ 2005",
"12-1-1997", "11 / 11 / 1918"
)It seems that the folks who entered the dates were not consistent in how to format them. In order to make analysis easier, it would be better if all the dates had exactly the same format. With the function str_replace_all() and regular expressions, this is not difficult:
dates %>%
str_replace_all(
pattern = "[- /]+",
replacement = "/"
)## [1] "3/14/1963" "4/13/2005" "12/1/1997" "11/11/1918"Here:
-
x(not explicitly seen above, due to the piping) is the text in which the substitution occurs; -
patternis the regex for the type of sub-string we want to replace; -
replacmentis what we want to replace matches of the pattern with.
The all in the name of the function means that we want to replace all occurrences of the pattern with the replacement text. There is also a str_replace() function that performs replacement only with the first match (if any) that it finds:
dates %>%
str_replace(
pattern = "[- /]+",
replacement = "/"
)## [1] "3/14 - 1963" "4/13/ 2005" "12/1-1997" "11/11 / 1918"In our application, that’s certainly NOT what we need. However, in cases where you happen to know that there will be at most one match, str_replace() gets the job done faster than str_replace_all(), which is forced to search through the entire string.
12.4.3 Patterned Replacement
In the dates example from Section 12.4.2 the replacement string (the argument for the parameter replacement) was constant: no matter what sort of match we found for the pattern [- /]+, we replaced it with the string “/”. It is important to note, however, that the argument provided for replacement can cause the replacement to vary depending upon the match found. In particular:
- It can include the back-references
\1,\2, …,\9. - It can be a defined function of the match.
Let’s look at an example. Here is a function that, given a string, will double all of the vowels that it finds:
doubleVowels <- function(str) {
str %>%
str_replace_all(
pattern = "([aeiou])",
replacement = "\\1\\1"
)
}
doubleVowels("Far and away the best!")## [1] "Faar aand aawaay thee beest!"Note that the pattern [aeiou] for vowels had to be enclosed in parentheses so that it could be captured and referred to by the back-reference \1. Also note that, since R converts the replacement string into a pattern, extra backslash escapes are required, just as in regular expressions.
Here is a function to capitalize every vowel found:
capVowels <- function(str) {
str %>%
str_replace_all(
pattern = "[aeiou]",
replacement = function(x) str_to_upper(x)
)
}
capVowels("Far and away the best!")## [1] "FAr And AwAy thE bEst!"Here is another function that searches for repeated words and encloses each pair in asterisks:
starRepeats <- function(str) {
str %>%
str_replace_all(
pattern = "\\b(\\w+) \\1\\b",
replacement = function(x) str_c("*", x, "*")
)
}
starRepeats("I have a boo boo on my knee knee.")## [1] "I have a *boo boo* on my *knee knee*."12.4.4 Detecting Matches
If you have many strings—in a character-vector, say—and you want to select those that contain a match to a particular pattern, then you want to use str_subset().
Consider, for example, the vector of strings:
sentences <- c(
"My name is Tom, Sir",
"And I'm Tulip!",
"Whereas my name is Lester."
)If we would like to find the strings that contain a word beginning with capital T, we could proceed as follows:
sentences %>%
str_subset(pattern = "\\bT\\w*\\b")## [1] "My name is Tom, Sir" "And I'm Tulip!"str_subset() returns a vector consisting of the elements of the vector sentences where the string contains at least one word beginning with “T”.
A related function is str_detect():
sentences %>%
str_detect(pattern = "\\bT\\w*\\b")## [1] TRUE TRUE FALSEstr_detect() returns a logical vector with TRUE where sentences has a capital-T word, FALSE otherwise.
Finally, str_locate() gives the positions in each string where a match begins:
sentences %>%
str_locate(pattern = "\\bT\\w*\\b")## start end
## [1,] 12 14
## [2,] 9 13
## [3,] NA NA12.4.5 Extracting Matches
If you require what is actually matched within each string you are processing, then you should look into str_extract() and str_extract_all().
As an example, let’s extract pairs of words beginning with the same letter in sentences2 defined below:
sentences2 <- c(
"The big bad wolf is walking warily to the cottage.",
"He huffs and he puffs peevishly.",
"He wears gnarly gargantuan bell bottoms!"
)
sentences2 %>%
str_extract(pattern = "\\b(\\w)\\w*\\W+\\1\\w*")## [1] "big bad" "puffs peevishly" "gnarly gargantuan"The results are returned as a character vector, in which each element is the first matching pair in the corresponding sentence.
If we want all of the matches in each sentence, then we use str_extract_all():
sentences2 %>%
str_extract_all(pattern = "\\b(\\w)\\w*\\W+\\1\\w*")## [[1]]
## [1] "big bad" "walking warily" "to the"
##
## [[2]]
## [1] "puffs peevishly"
##
## [[3]]
## [1] "gnarly gargantuan" "bell bottoms"Sometimes we want even more information. Suppose, for example, that we want not only the first matching word-pair, but also the repeated initial letter that permitted the match in the first place. In that case we need str_match():
## [,1] [,2]
## [1,] "big bad" "b"
## [2,] "puffs peevishly" "p"
## [3,] "gnarly gargantuan" "g"str_match() returns a matrix, each row of which corresponds to an element of sentences. The first column gives the value of the entire match, and the second column gives value of the capture-group in the regular expression. If the regular expression had used more capture groups, then the matrix would have had additional columns showing the values of the captures, in order.
If you want an analysis of all the matches in a string, then use str_match_all():
sentences2 %>%
str_match_all(pattern = "\\b(\\w)\\w*\\W+\\1\\w*")## [[1]]
## [,1] [,2]
## [1,] "big bad" "b"
## [2,] "walking warily" "w"
## [3,] "to the" "t"
##
## [[2]]
## [,1] [,2]
## [1,] "puffs peevishly" "p"
##
## [[3]]
## [,1] [,2]
## [1,] "gnarly gargantuan" "g"
## [2,] "bell bottoms" "b"The returned structure is a list and hence more complex, but you can query it for the values you need.
12.4.6 Extraction in Data Frames
Quite often you will want to manipulate strings in the context of working with a data frame. For this regex functions we have examined so far will be quite useful, but you should also know about the extract() function from the tidyr package, which is among the packages attached by the tidy-verse.
Imagine a data table that contains some names and phone numbers:
people <- data.frame(
name = c("Lauf, Bettina", "Bachchan, Abhishek", "Jones, Jenna"),
phone = c("(202) 415-3785", "4133372100", "310-231-4453")
)Each person has a standard ten-digit phone number, consisting of:
- the three-digit area code;
- the three digit central office number;
- the four-digit line number.
Suppose we would like to create three new variables in the data table, one for each of the three components of the phone number. For this, tidyr::extract() comes in handy:
people %>%
tidyr::extract(
col = phone,
into = c("area", "office", "line"),
regex = "(?x) # for comments
.* # in case of opening paren, etc.
(\\d{3}) # capture 1: area code
.* # possible separators
(\\d{3}) # capture 2: central office
.* # possible separators
(\\d{4}) # capture 3: line number
"
)## name area office line
## 1 Lauf, Bettina 202 415 3785
## 2 Bachchan, Abhishek 413 337 2100
## 3 Jones, Jenna 310 231 4453By default extract() removes the original column, but you can preserve it with remove = FALSE. (For the format of the regular expression in the above call, see the next sub-section.)
12.4.7 Counting Matches
The function str_count() provides a very convenient way to tally up the number of matches that a given regex has in a string. Here we use it to count the number of words in a string that begin with a lower or uppercase p.
strings <- c(
"Mary Poppins is practically perfect in every way!",
"The best-laid plans of mice and men gang oft astray.",
"Peter Piper picked a peck of pickled peppers."
)
strings %>%
str_count(pattern = "\\b[Pp]\\w*\\b")## [1] 3 1 6How might we find the words in a string that contain three or more of the same letter? In this case str_count() would not be useful. However we could try something like this:
"In Patagonia, the peerless Peter Piper picked a peck of pickled peppers." %>%
str_split("\\W+") %>%
unlist() %>%
str_subset(pattern = "([[:alpha:]]).*\\1.*\\1")## [1] "Patagonia" "peerless" "peppers"12.4.8 Regex Modes
If you have been practicing consistently with an online regex site, you will have noticed by now that a regex can be accompanied by various options. In most implementations they appear as letters after the closing regex delimiter, like this:
/regex/gm
Some of the most popular options are:
-
g: “global”, looking for all possible matches in the string; -
i: “case-insensitive” mode, so that letter-characters in the regex match both their upper and lower-case versions; -
m: “multiline” mode, so that the anchors^and$are attached to newlines within the string rather than to the absolute beginning and end of the string; -
x: “white-space” mode, where white-spaces in the regex are ignored unless they are escaped (useful for lining out the regex and inserting comments to explain its operation).
Since stringr has both global and non-global versions of regex functions you probably will not bother with g, but the other options—known technically as modes—can sometimes be useful.
If you would like to set modes to apply to your entire regex, insert it (or them) like this at the beginning of the expression:
(?im)t[aeiou]{1,3}$
In the example above, we are in both case-insensitive and multiline mode, and we are looking for t or T followed by 1, 2 or 3 vowels (upper or lower) at the end of any line in a (possibly) multiline string.
Following is an example of the mode to ignore white-space and to ignore case:
myPattern <-
"(?xi) # ignore whitespace (x) and ignore case (i)
\\b # assert a word-boundary
(\\w) # capture the first letter of the first word
\\w* # rest of the first word
\\W+ # one or more non-word characters
\\1 # repeat the letter captured previously
\\w* # rest of the second word
"
sentences2 %>%
str_match_all(pattern = myPattern)## [[1]]
## [,1] [,2]
## [1,] "big bad" "b"
## [2,] "walking warily" "w"
## [3,] "to the" "t"
##
## [[2]]
## [,1] [,2]
## [1,] "He huffs" "H"
## [2,] "puffs peevishly" "p"
##
## [[3]]
## [,1] [,2]
## [1,] "gnarly gargantuan" "g"
## [2,] "bell bottoms" "b"Due to the presence of x-flag at the very beginning of the regex, the regex engine knows to ignore white-space throughout, and it will also ignore hash-tags and whatever comes after them on a line. This permits the placement of comments within the regular expression. The i-flag directs the regex engine to ignore case when looking for matches. Accordingly, in the example we pick up the extra match “he huffs”.
Some people prefer to control regular-expression modes by means of stringr’s regex() function:
myPattern <- regex(
pattern = "
\\b # assert a word-boundary
(\\w) # capture the first letter of the first word
\\w* # rest of the first word
\\W+ # one or more non-word characters
\\1 # repeat the letter captured previously
\\w* # rest of the second word
",
comments = TRUE,
ignore_case = TRUE
)
sentences2 %>%
str_match_all(pattern = myPattern)## [[1]]
## [,1] [,2]
## [1,] "big bad" "b"
## [2,] "walking warily" "w"
## [3,] "to the" "t"
##
## [[2]]
## [,1] [,2]
## [1,] "He huffs" "H"
## [2,] "puffs peevishly" "p"
##
## [[3]]
## [,1] [,2]
## [1,] "gnarly gargantuan" "g"
## [2,] "bell bottoms" "b"12.4.9 Practice Exercises
The stringr package comes with fruit, a character-vector of giving the names of 80 fruits.
Determine how many fruit-names consist of exactly two words.
Find the two-word fruit-names.
Find the indices of the two-word fruit names.
Find the one-word fruit-names that end in “berry”.
Find the fruit-names that contain more than three vowels.
In the word “banana” the string “an” appears twice in succession, as does the string “na”. Find the fruit-names containing at least one string of length two or more that appears twice in succession.
To the
peopledata frame from this section, add two new variables:firstfor the first name andlastfor the last name. The originalnamevariable should be removed.
12.4.10 Solutions to the Practice Exercises
-
Try this:
## [1] 11 -
Try this:
## [1] "bell pepper" "blood orange" "canary melon" "chili pepper" ## [5] "goji berry" "kiwi fruit" "purple mangosteen" "rock melon" ## [9] "salal berry" "star fruit" "ugli fruit"Another way is as follows:
fruit %>% str_subset("^\\w+\\s+\\w+$")## [1] "bell pepper" "blood orange" "canary melon" "chili pepper" ## [5] "goji berry" "kiwi fruit" "purple mangosteen" "rock melon" ## [9] "salal berry" "star fruit" "ugli fruit" -
Try this:
fruit %>% str_detect("^\\w+\\s+\\w+$") %>% which()## [1] 5 9 13 17 32 42 66 72 73 75 79 -
Try this:
fruit %>% str_subset("\\w+berry$")## [1] "bilberry" "blackberry" "blueberry" "boysenberry" "cloudberry" "cranberry" ## [7] "elderberry" "gooseberry" "huckleberry" "mulberry" "raspberry" "strawberry" -
Try this:
## [1] "avocado" "blood orange" "breadfruit" "canary melon" ## [5] "cantaloupe" "cherimoya" "chili pepper" "clementine" ## [9] "dragonfruit" "feijoa" "gooseberry" "grapefruit" ## [13] "kiwi fruit" "mandarine" "nectarine" "passionfruit" ## [17] "pineapple" "pomegranate" "purple mangosteen" "tamarillo" ## [21] "tangerine" "ugli fruit" "watermelon" -
Try this:
fruit %>% str_subset("(\\w{2,})\\1")## [1] "banana" "coconut" "cucumber" "jujube" "papaya" "salal berry" -
Try this:
## last first phone ## 1 Lauf Bettina (202) 415-3785 ## 2 Bachchan Abhishek 4133372100 ## 3 Jones Jenna 310-231-4453
12.5 Application: Amazon Book Reviews
The R-package tigerData (White 2021) contains the data set reviews, a collection of user-reviews on Amazon for seven bestsellers. Learn more about the data set as follows:
Each row of the data frame contains:
- the 1-5 rating that the reviewer assigned to the book
- a URL fragment that locates the review online;
- the summary-title of the review;
- the content of the review itself.
Let’s focus on reviews for Hunger Games series. The following code creates a new data frame that contains only those reviews:
hunger <- subset(reviews, book == "hunger")That’s still a lot of reviews! We can tell by asking for the number of rows in the hunger data frame:
nrow(hunger)## [1] 24027We are looking at 24,027 reviews—some of which, by the way, are quite long.
Explore the plain-text of some of the reviews. For example, the text of the second review can be viewed with:
hunger$content[2]## # A single long string. We will show just the first few characters:
## [1] "\"<span class=\"\"a-size-base review-text\"\">Clearly ...Perusing this review, we come upon the following passage:
There is a certain strain of book that can hypnotize you into believing that you are in another time and place roughly 2.3 seconds after you put that book down. <a class=\“\”a-link-normal\“\” href=""/Life-As-We-Knew-It/dp/0152061541\“\”>Life As We Knew It by Susan Beth Pfeffer could convince me that there were simply not enough canned goods in my home.
The author has linked to another book sold on Amazon, Susan Beth Pfeffer’s Life As We Knew It. The Amazon.com URL for the book is found by prepending the company’s domain to the URL-fragment seen in the excerpt above, resulting in the link:
We might be curious to know what other books on Amazon our reviewers link to when they are discussing the Hunger Games. Regular expressions can help us to extract the links from the mass of text in hunger$content.
All of the Amazon links are generated for the user by the computer, so they will all have the same format. Hence we can use a look-behind and a look-ahead to construct a regex that will be matched by any URL-fragment within such an anchor:
(?<=<a class=\\"\\"a-link-normal\\"\\" href=\\"\\")(.+?)(?=\\"\\">)
Checking carefully, we see that none of the tokens require extra escaping: we can use this text as our pattern in regex function in R:
linkPattern <- '(?<=<a class=\\"\\"a-link-normal\\"\\" href=\\"\\")(.+?)(?=\\"\\">)'First we create a new variable in hunger that counts the number of links in a review:
Now we can tally the number of links:
## # A tibble: 10 × 2
## linkCount n
## <int> <int>
## 1 0 23854
## 2 1 110
## 3 2 34
## 4 3 15
## 5 4 7
## 6 5 3
## 7 6 1
## 8 7 1
## 9 8 1
## 10 9 1If you are generating a report with R Markdown, then a better-looking table (see Table 12.4 can be produced as follows:
hungerLinks %>%
group_by(linkCount) %>%
summarise(n = n()) %>%
knitr::kable(
caption=str_c(
"Table showing number of links ",
"made by reviewers of the Hunger ",
"Games series."
)
)| linkCount | n |
|---|---|
| 0 | 23854 |
| 1 | 110 |
| 2 | 34 |
| 3 | 15 |
| 4 | 7 |
| 5 | 3 |
| 6 | 1 |
| 7 | 1 |
| 8 | 1 |
| 9 | 1 |
Most of the reviewers didn’t link at all, but 173 of them did provide at least one link. One reviewer linked to nine books! Let’s find them and add the base URL http://www.amazon.com/:
hungerLinks %>%
filter(linkCount == max(linkCount)) %>% # get the case having most links
.$content %>% # get just the content of the review,
# a character vector (of length 1 since there
# is only one review with the max number of lengths)
str_extract_all(pattern = linkPattern) %>% # get the matches,
# but this is a list of
# length 1 ...
unlist() %>% # ... so unlist it into a character vector
str_c("http://www.amazon.com/", .) # prepend the base URL to each link## [1] "http://www.amazon.com//Harry-Potter-Paperback-Box-Set-Books-1-7/dp/0545162076"
## [2] "http://www.amazon.com//The-Dark-Tower-Boxed-Set-Books-1-4/dp/0451211243"
## [3] "http://www.amazon.com//The-Long-Walk/dp/0451196716"
## [4] "http://www.amazon.com//Battle-Royale-The-Novel/dp/1421527723"
## [5] "http://www.amazon.com//Battle-Royale-The-Complete-Collection-Blu-ray/dp/B006L4MX4A"
## [6] "http://www.amazon.com//The-Dark-Tower-Boxed-Set-Books-1-4/dp/0451211243"
## [7] "http://www.amazon.com//Harry-Potter-Paperback-Box-Set-Books-1-7/dp/0545162076"
## [8] "http://www.amazon.com//Abarat/dp/0062094106"
## [9] "http://www.amazon.com//lord-of-the-flies/dp/B0073SQWWC"As we learn more about R’s data-analysis functions we’ll be able to explore a wide variety of interesting questions about the attitudes and practices of Amazon reviewers. This will involve plowing through a lot more text, but now that we know regular expressions we are sure to “save the day”!
12.5.1 Practice Exercises
Use
reviewsto generate a table of the the number of Amazon links in reviews of John Greene’s book The Fault in our Stars.How many times did a reviewer link to Looking for Alaska (another well-known book by John Greene)?
From
reviews, make a data frame called shades that contains the reviews of Fifty Shades of Gray. This bestseller received an unusually high proportion of low ratings. Think of a few choice words that might show up in a negative review and create a logical variable calleddislikesthat isTRUEwhen one or more of these words appears in the review, and isFALSEotherwise. Convert the numerical variableratingto a factor variable. Make a bar graph that shows the relation betweendislikesandrating.
12.5.2 Solutions to the Practice Exercises
-
Try this:
linkPattern <- "(?<=<a class=\"\"a-link-normal\"\" href=\"\"/)(.+?)(?=\"\">)" fault <- reviews %>% filter(book == "fault") fault %>% mutate(linkCount = str_count(content, linkPattern)) %>% group_by(linkCount) %>% summarise(n = n())## # A tibble: 6 × 2 ## linkCount n ## <int> <int> ## 1 0 35827 ## 2 1 10 ## 3 2 3 ## 4 3 2 ## 5 6 1 ## 6 7 1 -
Try this:
fault %>% .$content %>% str_extract_all(pattern = linkPattern) %>% unlist() %>% str_detect("(?i)Looking-For-Alaska") %>% sum()## [1] 5 -
Here is one possibility:
reviews %>% filter(book == "shades") %>% mutate(dislikes = str_detect( content, "bad|awful|terrible|waste" ) ) %>% mutate(rating = factor(rating)) %>% ggplot(aes(x = rating)) + geom_bar(aes(fill = dislikes), position = "dodge")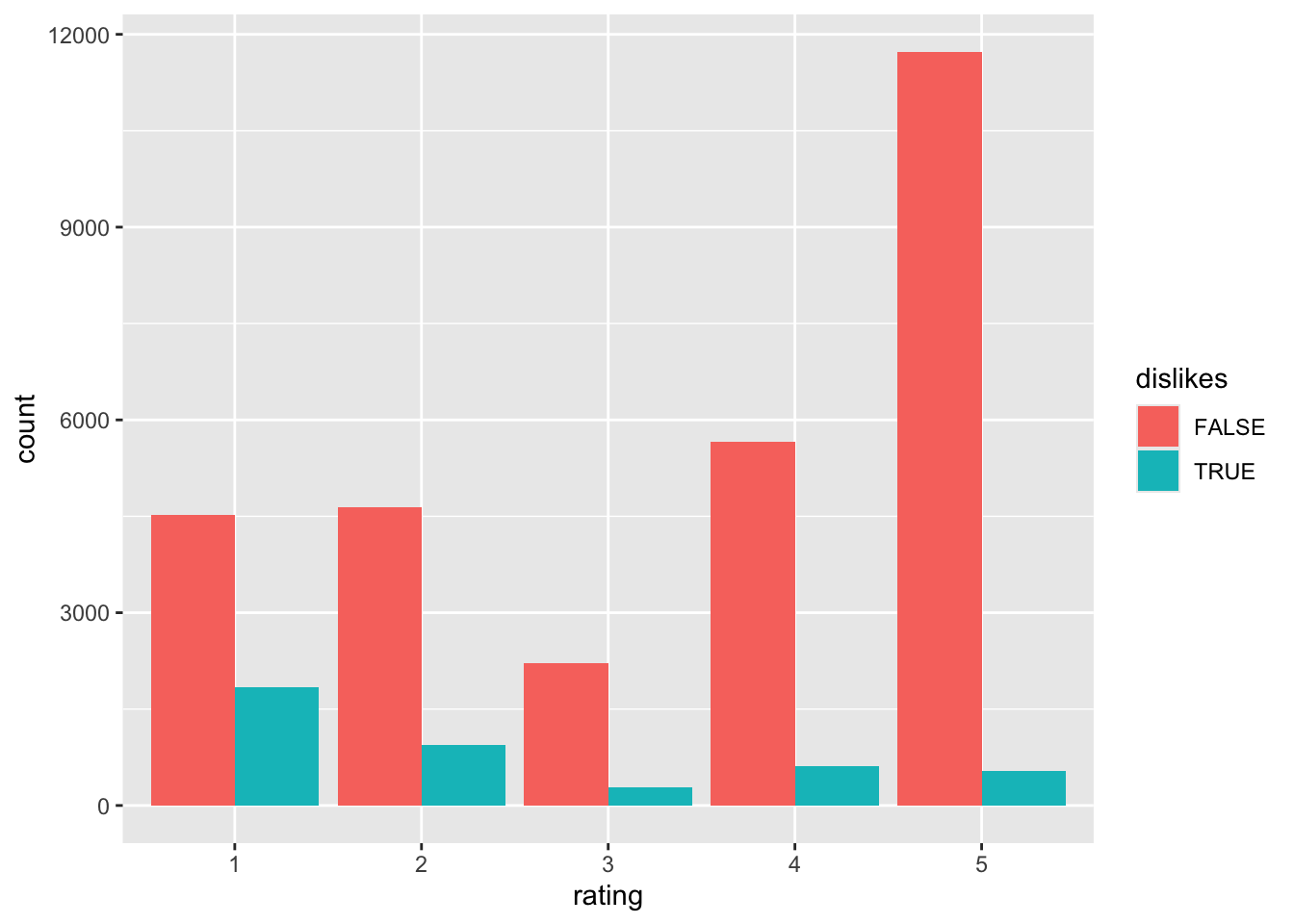
Glossary
- Regular Expression
-
A sequence of characters that represents a pattern.
- Regular Expression Engine
-
A specific implementation of regular expressions used by a specific programming language.
- Literal Character
-
A character in a regular expression that matches itself.
- Character Class
-
A set of characters enclosed in brackets. It matches any one of the characters in the set.
- Metacharacter (also called “Special Character”)
-
A character in a regular expression that does not match itself, but instead has a special role in specifying the overall pattern.
Exercises

-
Write a function called
findMister()that, when given any string, will return a character vector of the words that immediately follow the string “Mister”, with exactly one space in between. The function should take a single argument calledstr, the string to search. A typical example of use is as follows:text <- "Here are Mister Tom, MisterJerry, Mister Mister, and Mister\tJoe." findMister(text)## [1] "Tom" "Mister" -
Write a function called
findMr()that, when given any string, will return a character vector of all words following the string “Mr.”, with exactly one space in between. The function should take a single argument calledstr, the string to search. A typical example of use is as follows:text <- "Here are Mr. Tom, Mr Jerry, Mr. Mister, and Mr.\tJoe." findMr(text)## [1] "Tom" "Mister" -
For each of the following expressions, write a regular expression to test whether any of the sub-string(s) described occur in a given string. The regular expression should match any of the sub-strings described, and should not match any other sub-string. Try to make the regular expression as short as possible. Write the regular expression as a string that could be used in one of R’s regex functions (i.e. extra backslash escapes as needed). The first item is done for you, as an example.
-
bot and bat. Regex string:
"b[oa]t". (This is the one to submit, because it’s shorter than other alternatives such as"box|bat"). - cart and cars and carp.
- slick and sick
- Any word ending in ity (such as velocity and ferocity). Be sure to pay attention to word-boundaries. You should match velocity but not velocity (includes a space before the “v”) or velocity;.
- A whole number consisting of more than six digits.
- A word that is between 3 and 6 characters long. Pay attention to word-boundaries.
- One or more white-space characters, followed by a hyphen or a semicolon or a colon.
-
bot and bat. Regex string:
-
Write a function called
findTitled()that, when given any string, will return a character vector of all words following any one of these titles:- “Mr.”
- “Mister”
- “Missus”
- “Mrs.”
- “Miss”
- “Ms.”
There should be exactly one space between the title and the following word. The function should take a single argument called
str, the string to search. A typical example of use is as follows:text <- "Here are Mr. Tom, Ms. Thatcher, Miss Ellen, and Helen." findTitled(text)## [1] "Tom" "Thatcher" "Ellen" -
Write a function called
capRepeats()that, when given a string, searches for all repeated-word pairs (with at least one character of white-space in between) and replaces them with the same pair where all letters are capitalized. The function should take a single argument calledstr, the string to be searched. A typical example of use would be as follows:capRepeats("I have a boo boo on my knee \tknee!")## [1] "I have a BOO BOO on my KNEE \tKNEE!" -
Use
str_subset()to write a function calledlongWord()that, when given a character vector of strings, returns a vector consisting of the strings that contain a word at least eight characters long. The function should take a single argument calledstrs. An example of use would be:myText <- c("Very short words.", "Got a gargantuan word.", "More short words!") longWord(strs = myText)## [1] "Got a gargantuan word." -
Write a function called
longWord2()that, when given a character vector of strings, returns a list of character vectors, where each vector consists of the words in the corresponding string that are at least eight characters long. The function should take a single argument calledstrs. An example of use would be:myText <- c("Very short words.", "Got a gargantuan word.", "More short words!") longWord2(strs = myText)## [[1]] ## character(0) ## ## [[2]] ## [1] "gargantuan" ## ## [[3]] ## character(0) -
Write a function called
phoneNumber()that, when given a vector of strings returns a logical vector indicating which of the strings contain a valid phone number. For our purposes a valid phone number shall be any string of the formxxx-xxx-xxxx
or
xxx.xxx.xxxx
Thus, 502-863-8111 is valid and so is 502.863.8111, but not 502-863.8111.
In the code for the function, specify the pattern using
(?x)so you can ignore whitespace and leave detailed comments for each portion of the regular expression.The function should take a single parameter called
strs. A typical example of use would be:sentences <- c( "Ted's number is 606-255-3143.", "Rhonda's number is 403-28-1259.", "Lydia's number is 502.255.3921.", "Raj's number is 502.367-4432." ) phoneNumber(strs = sentences)## [1] TRUE FALSE TRUE FALSE