Using lattice’s histogram()
Preliminaries
The function histogram() is used to study the distribution of a numerical variable. It comes from the lattice package for statistical graphics, which is pre-installed with every distribution of R. Also, package tigerstats depends on lattice, so if you load tigerstats:
require(tigerstats)then lattice will be loaded as well. If you don’t plan to use tigerstats but you want to use the function histogram(), then make sure you load lattice:
require(lattice)Note: If you are not working with the R Studio server hosted by Georgetown College, then you will need to install tigerstats on your own machine. You can get the current version from Github by first installing the devtools package from the CRAN repository, and then running the following commands in a fresh R session:
require(devtools)
install_github(repo="homerhanumat/tigerstats")In this tutorial we will also use a function from the mosaic package, so let’s make sure it is loaded:
require(mosaic)One Numerical Variable
In the m11survey data frame from the tigerstats package, suppose that you want to study the distribution of fastest, the fastest speed one has ever driven. You can do so with the following command:
histogram(~fastest,data=m111survey,
type="density",
xlab="speed (mph)",
main="Fastest Speed Ever Driven")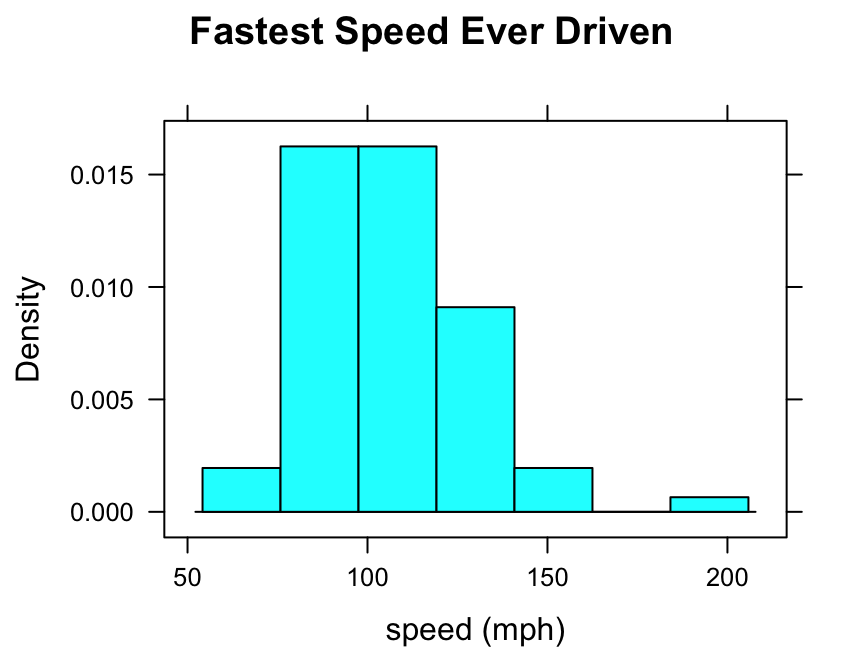
Note the use of:
- the
xlabargument to label the horizontal axis, complete with units (miles per hour); - the
mainargument to provide a brief but descriptive title for the graph; - the
typeargument to make a density histogram (we like this type the most, but other possible types are “count” and “percent”).
Controlling Breaks
One of the most important ways to customize a histogram is to to set your own values for the left and right-hand boundaries of the rectangles.
In order to accomplish this, you should first know the range of your data values. You can find this quickly using the favstats() function from package mosaic:
favstats(~fastest,data=m111survey)## min Q1 median Q3 max mean sd n missing
## 60 90.5 102 119.5 190 105.9014 20.8773 71 0The minimum fastest speed is 60 mph, and the maximum fastest speed is 190 mph.
One possible choice for rectangle boundaries is to have the left-most rectangle begin at sixty, and then have each rectangle be 10 mph wide at the base, finally reaching a rectangle that ends at 190 mph. In other words, we want the rectangle boundaries to be:
\[60,70,80,90,100,110,120,130,140,150,160,170,280,190.\]
These numbers will be the “breaks” for the rectangles in our histogram. We can set these breaks by putting them, as a list, into the breaks argument of the histogram() function, as follows:
histogram(~fastest,data=m111survey,
type="density",
xlab="speed (mph)",
main="Fastest Speed Ever Driven",
breaks=c(60,70,80,90,100,110,120,130,
140,150,160,170,180,190))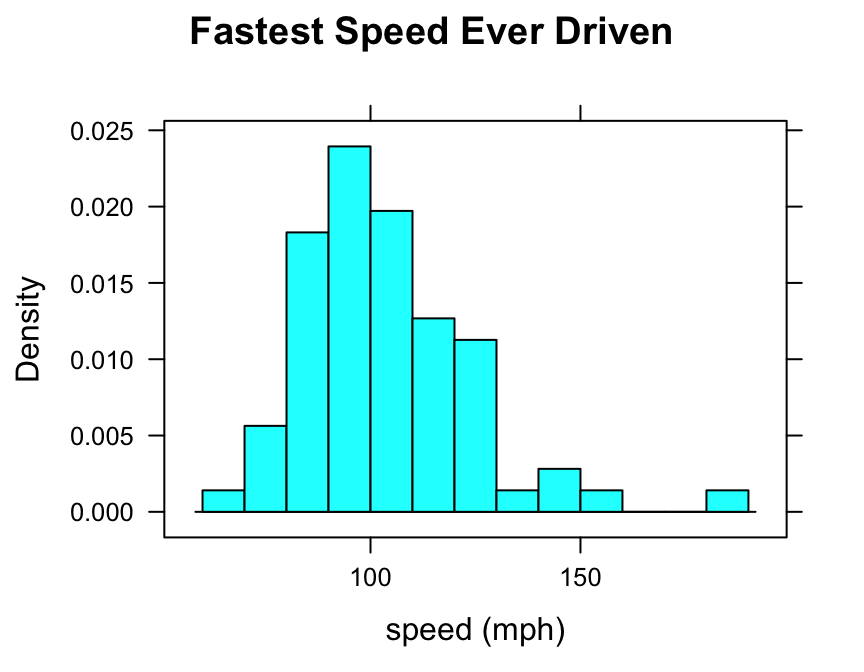
You can accomplish the same thing with less typing, if you make use of the seq() function:
histogram(~fastest,data=m111survey,
type="density",
xlab="speed (mph)",
main="Fastest Speed Ever Driven",
breaks=seq(from=60,to=190,by=10))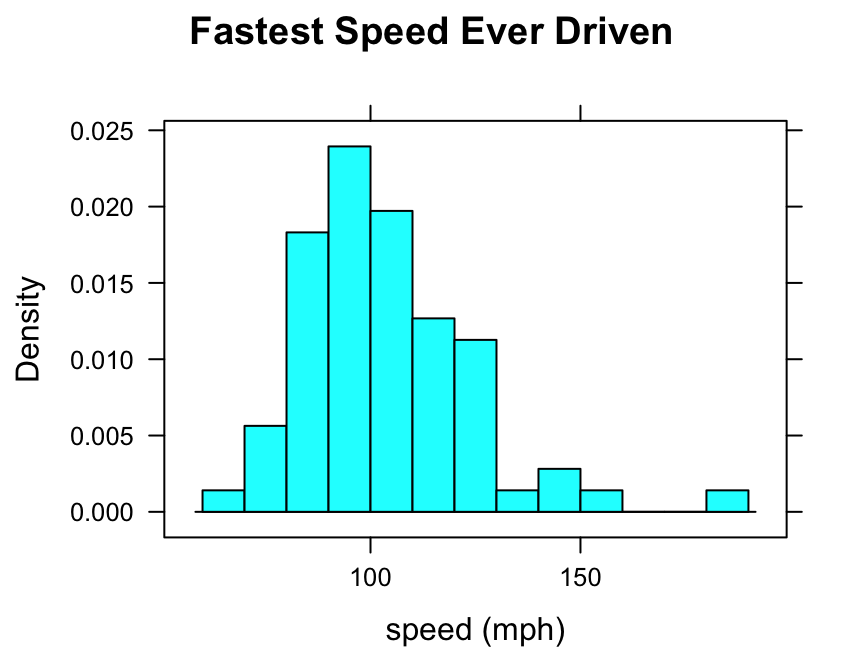
Numerical and Factor Variable
Suppose you want to know:
Who tends to drive faster: guys or gals?
Then you might wish to study the relationship between the numerical variable fastest and the factor variable sex. You can use histograms in order to perform such a study.
Try this code:
histogram(~fastest|sex,data=m111survey,
type="density",
xlab="speed (mph)",
main="Fastest Speed Ever Driven,\nby Sex",
breaks=seq(from=60,to=190,by=10))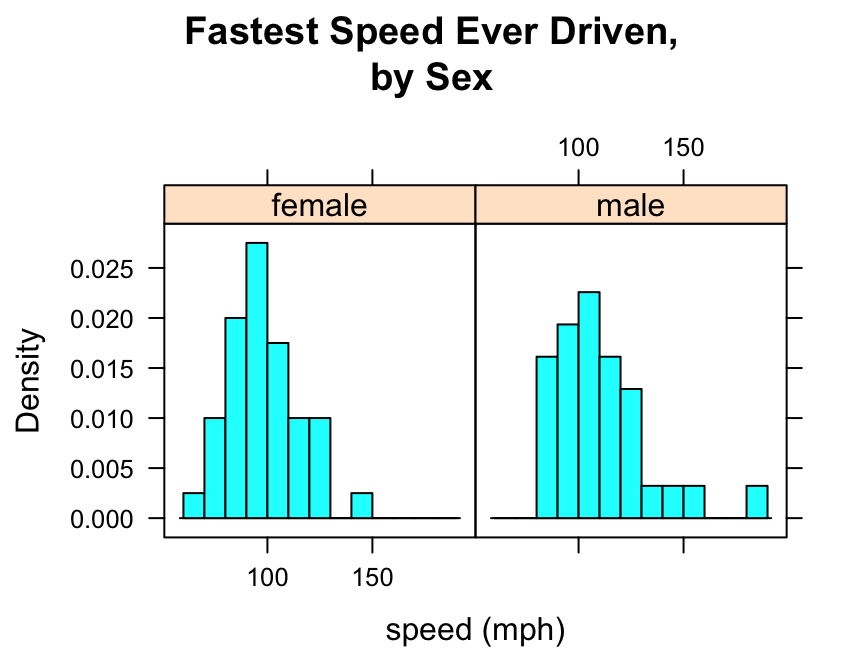
Note that to produce side-by-side histograms, you facet on the factor variable with the formula:
\[\sim numerical\ \vert \ factor\]
Note also the use of “\n” to split the title into two lines: this is a useful trick when the title is long.
You can also adjust the layout of the separate panels to your liking:
histogram(~fastest|sex,data=m111survey,
type="density",
xlab="speed (mph)",
main="Fastest Speed Ever Driven,\nby Sex",
breaks=seq(from=60,to=190,by=10),
layout=c(1,2))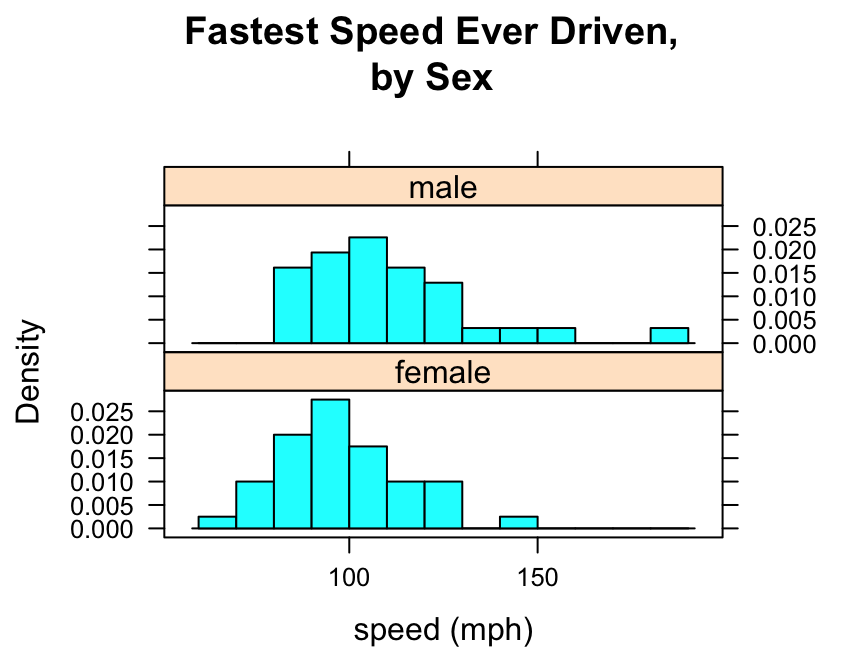
Additional Variables
We saw above that you can incorporate additional variables into your analysis by facetting, i.e., producing a plot with separate panels for each of several subgroups of the observations, as determined by a separate variable. You can also do this with two other variables, and they don’t have to be factors!
Suppose, for example, that we would like to study the relationship the fastest speed ever driven, but to break the subjects down further into groups determined by their height and by where they prefer to sit in a classroom. The following code accomplishes this:
Height <- equal.count(m111survey$height, number = 2, overlap = 0.1)
histogram(~fastest | Height * seat,
data = m111survey,
layout = c(2,3))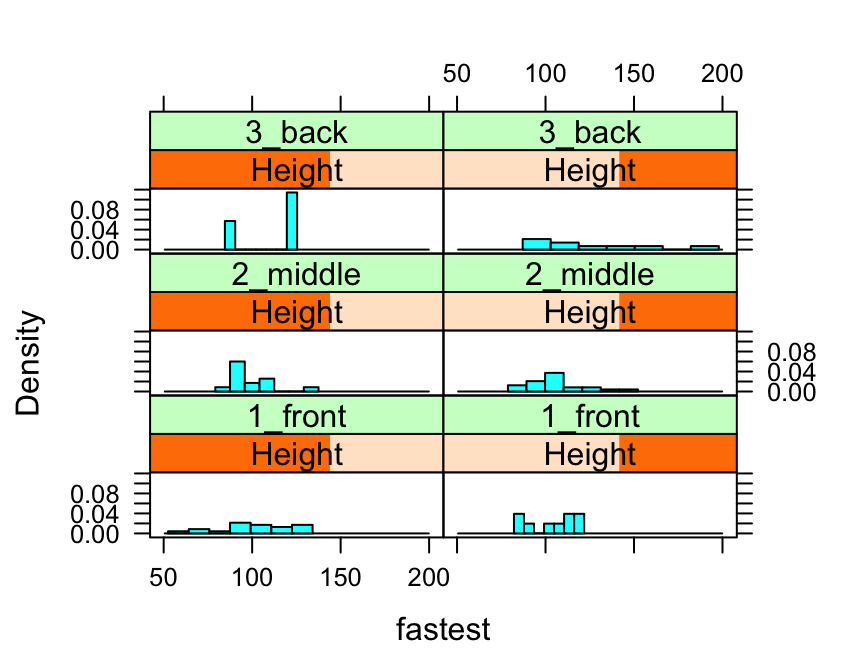
In the code above, the line:
Height <- equal.count(m111survey$height, number = 2, overlap = 0.1)prepares us to facet by height. The equal.count() function takes a numerical variable and divides its values into groups of approximately equal size. The number of the groups is specified by the number argument. In this case we are asking for two groups: “shorter” students and “taller” students. The groups are permitted to contain some members in common, and the allowed percentage intersection is specified by the overlap argument. (Setting overlap = 0 would result in completely disjoint groups.) The new variable Height is called a shingle, but you can think of it as a factor variable with two values: shorter and taller.
The formula fastest ~ sex | Height * seat facets by Height and seat. The variables by which you facet appear after a | bar, anf if you facet by two variables then you must separate them with a *. SinceHeight has two values and `seat has three values and \(2 \times 3 = 6\), we arrive at a plot with six panels.
The layout argument determines the number of rows and columns in our facet-ted plot. Setting layout to c(2,3) specified two columns and three rows. (Note that the columns are specified first!)
Further Refinements
For some other refinements, consult the Lattice Histogram Addin in RStudio.